5. Job Submission
In principle, this workflow treats the actual experiment as one big chain job
– so individual jobs are executed one after another with different dependencies.
The configuration of the submission of this chain job is done in the
ctrl/starter.sh file. At a first glance this may seem a bit complex, that the
figure below should help you to understand the different terminology used.
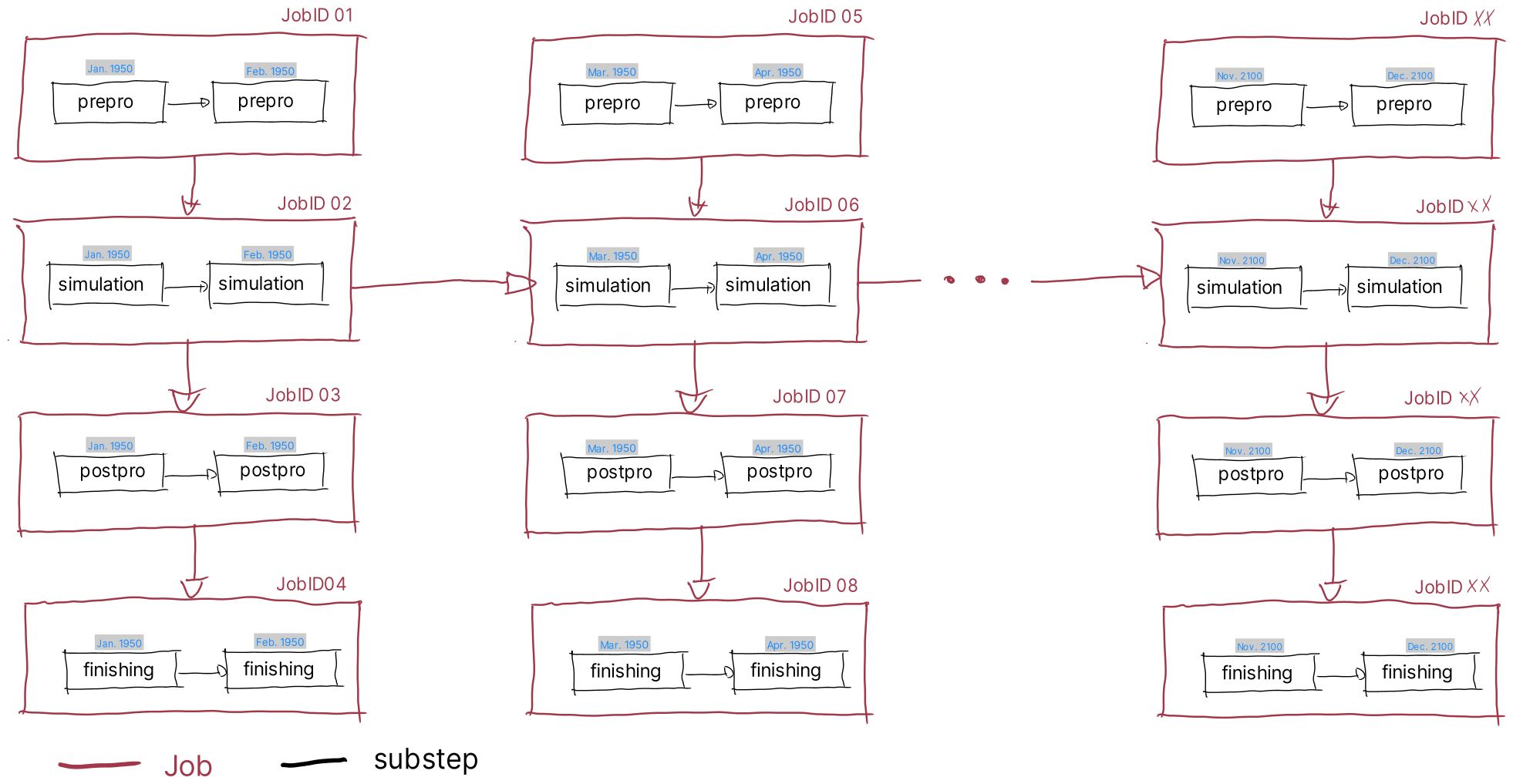
So the whole experiment (lets assume a climate simulation from 1950 to 2100)
consists of several jobs. Each job does runs a specific substep for several
months. Dependencies between these jobs are indicated by arrows.
For example, the job containing the simulation for Jan. and Feb. 1950 cannot
start before the job containing the prepro for the same months has finished.
Furthermore, the jobs that contain the prepro substeps do not see any
dependency, so all these jobs can run in parallel. This type of dependency
ensures that the jobs containing the simulation substeps, the most
computetime intense substep, run in sequence and do not wait for other
processes than really needed. Jobs containing subsequent substeps will run in
parallel with the simulation job, once the dependency has been satisfied.
This is done to ‘offload’ as much compute-power as possible from the actual
simulation job in order to increase the performance of the overall experiment.
Combining multiple substeps into a single job - in the image above running simulations for two months in one job - is one approach to making the most efficient use of HPC resources. Jobs on an HPC system are not executed directly, but sent to a job scheduler, which manages which job to run at what time on which compute node. So you have to wait for your job to run until your job is first in a long queue of jobs. The starting position in this queue is determined not only by the time of submission, but also by a priority system. At JSC, this system prioritizes big jobs, because that is what JSC systems are built for. So to increase the size of our jobs, we collect e.g. several months in one job to increase the job priority and to reduce queueing time.
Below is an example of how to control all this in the ctrl/starter.sh file.
Let’s assume we want to run the months Jan. to Apr. of 1950, and to increase
priority of our jobs, we want to collect two months in one job. So, in
principle, replicate the first two columns in the image above. To do so, we
need to set the following in ctrl/starter.sh:
We need to set
simLength='1 month'because we want asimulationsubstep to simulate one month. In principle you can also set this to10 daysor2 monthsetc. to individually change the simulation length of asimulationsubstep.We need to set
startDate="1950-01-01T00:00Z"andinitDate="1950-01-01T00:00Z", as we want to start with Jan. 1950. TheinitDatethereby indicates when the experiment starts and does not change during the whole experiment. ThestartDateindicates when the current job should start, and therefore changes with each job you submit. For the first job submitted in an experiment, both are equal, as in our case.We need to set
NoS=4, as we want to submit 4simulationsubsteps. As we setsimLength='1 month'before, we do simulate 4 months with this setting.We need to set
simPerJob=2, as we want to collect twosimulationsubsteps in one job, to increase the priority.
With this information, the workflow groups all substeps and submits the required jobs with all necessary dependencies.
A small note on the naming / wording used:
As the core of all substeps is the simulation substep, the terminology is
based on this. So we set a simLength (simulation length), but this is also
affecting the other substeps as prepro, postpro, and finishing. Further we
set NoS (Number of Simulations), but also determine the number of
postpro, and finishing substeps etc. Similar for simPerJob.